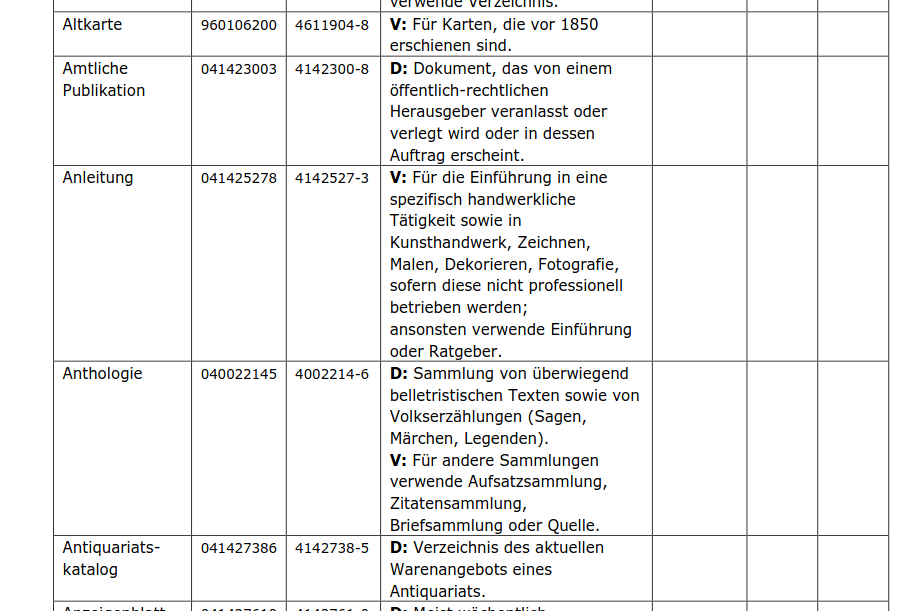
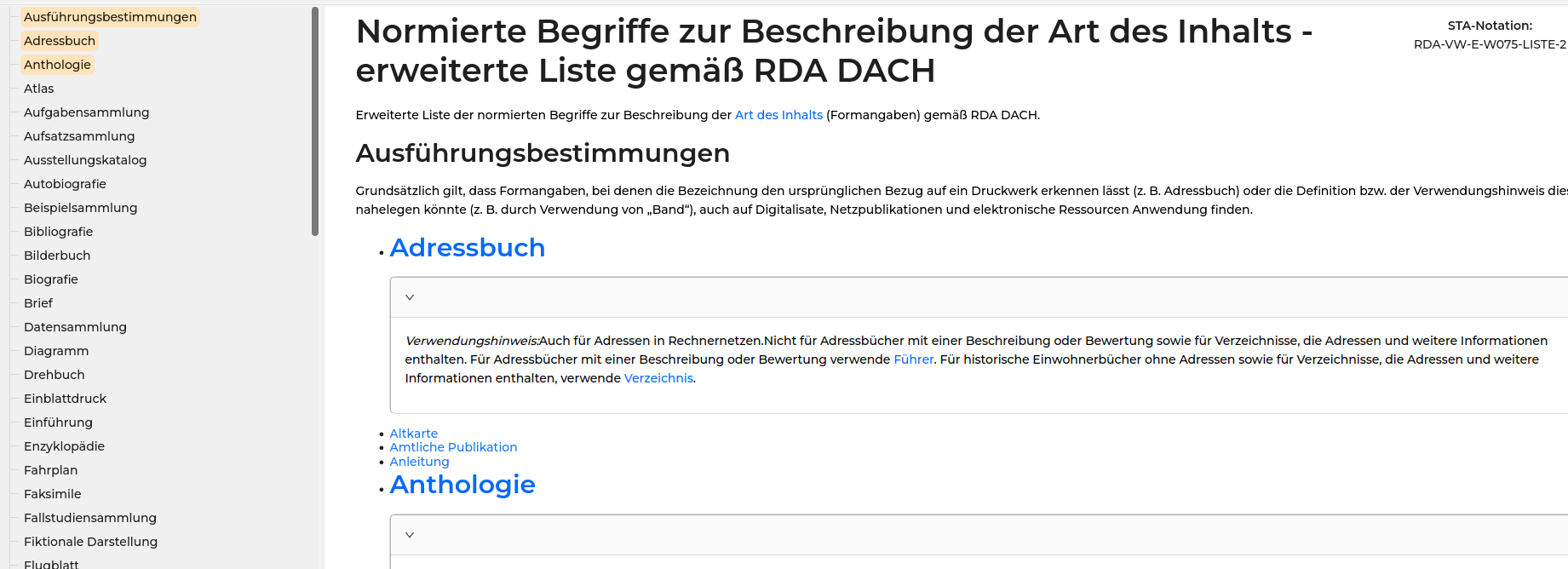
Jetzt wollte ich die Tabelle aktualisieren und habe gesehen, dass in der neusten Version auf der RDA-Dokumenten-Seite „nur“ auf die RDA-Dach Seite verlinkt wird, aber keine PDF mit Tabelle mehr vorhanden ist. Gibt es irgendwo eine Tabelle mit allen aktuellen Inhaltsbegriffen?
ich kenn mich nicht so gut mit den Arbeitshilfen aus, daher wäre ich über Hilfe sehr froh.
Interessant wäre auch, ob diese Umstellung auf RDA-Dach statt PDF für die anderen Arbeitshilfen geplant ist, da wir noch mehr Konkordanzen aus den Arbeitshilfen bauen.
Wenn man die Wikibase-Daten mit SPARQL abfragen kann, solltest du die Liste mit einer Abfrage automatisch erstellen können. Ich habe aber keinen SPARQL-Endpunkt oder Query-Editor gefunden. @bfisch , kannst du uns da vielleicht weiterhelfen?
Bei der BiblioCon25 hatten @Tracy_Arndt und ich nochmal über SPARQL-Queries o.ä. gegen https://sta.dnb.de/ gesprochen. Es ist ja toll, dass die Informationen strukturiert in Wikibase erfasst werden. Wenn ich das richtig sehe, gibt es aber lediglich die Wikibase-API als Möglichkeit, an die strukturierten Daten zu kommen. Im konkreten Fall, um die Werte der Liste und ihre Benennungen zu bekommen, ist das aber nicht mit bloß einer API-Abfrage möglich, oder? Mit wbgetentities und wbgetclaims fehlen jedenfalls die Labels der kontrollierten Werte. ]Wenn ich richtig liege, müsste mensch also scripten, um die gewünschten Daten zu extrahieren. Ein SPARQL Endpoint wäre da deutlich komfortabler.
Ich kenne mich mit Wikibase nicht so aus, könnte mir aber vorstellen, dass es den SPARQL Endpoint schon gibt, er nur nicht für die freie Nutzung konfiguriert ist. @SarahHartmann , kannst du da was zu sagen?
Danke für den Hinweis. Da wir nicht mit Pica-Abzügen arbeiten, habe ich das jetzt mal in lobid-gnd versucht, was ja auch ein komfortabler Weg wäre. Offenbar gibt es im GND-RDF bisher keinen semantischen Marker für Formschlagwörter und Suchen nach Textstrings sind ungenau:
Suche nach „AH-007“ (das in den Feldern definition und usageInstructions vorkommt) gibt nicht alle Ergebnisse zurück, denn es müssten glaube ich 164 sein.
Also grundsätzlich ist es möglich alle Inhalte der STA-Plattform über den integrierten SPARQL-Endpoint der Wikibase-Instanz abzurufen (https://sta.dnb.de/query/).
Allerdings benötigt man dafür Hintergrundinformationen zur Datenmodellierung der Dokumentation, die wir (bislang) nicht dokumentiert haben und das steht auch leider gerade nicht auf unserer Prioliste ganz oben, weil wir aktuell mit der Integration der GND-Dokumentation beschäftigt sind.
Aber vielleicht hilft euch das schon einmal weiter, um die SPARQL-Abfrage zu bauen:
In der Dokumentation sind es für diesen Fall Vorgabewerte, die in drei verschiedene Listen - das erweiterte, optionale und enge Set - zusammengestellt sind.
Und dann könnt ihr jeweils das Label (den Bestandteil hinter dem Pipe muss rausgefiltert werden) und den GND-Identifier (Property:P295) rausziehen.
Beispiel: Q2659
Über die GND oder lobid solltet ihr die Liste über die Entitätencodes „saz“ und „saf“ selektieren können, die Sachschlagwörter der Liste für das RDA-Element „Art des Inhalts“ sind mit beiden Entitätencodes versehen bzw. doppelt codiert also mit „saz“ und „saf“ (217 Datensätze)
Bitte auch die Definitionen und die Verwendungshinweise bei der Verwendung der Liste berücksichtigen.
Danke, den habe ich selbst nicht gefunden. Leider scheint es momentan nicht zu funktionieren, zumindest nicht so, wie ich es von Wikidata gewohnt bin. Ich habe mal mit folgendem angefangen:
# AH-007-Liste mit Labels
BASE <https://sta.dnb.de/entity/>
SELECT ?item ?itemLabel
WHERE
{
<Q2657> <P8> ?item .
SERVICE wikibase:label { bd:serviceParam wikibase:language "de". }
}
Wenn ich das absende, wird im Browser weder das Ergebnis oder eine Fehlermeldung angezeigt. Stattdessen wird eine Datei sparql.srx heruntergeladen, die aber auch nicht von beiden enthält, sondern lediglich:
da ich mich gerade auch damit beschäftige, wollte ich hier mitteilen, dass deine Anfrage einen kleinen Fehler enthält. Für die Properties musst du einen anderen Namespace angeben.
Siehe hier:
Dann müsste ich jetzt “nur” noch lernen wie ich den GND identifier Property:P295 dazuhole, dann könnten wir bei Lobid eine neue Lookup-Tabelle erzeugen.