Ich frage mich regelmäßig, wieviele Bots darunter sind, die das Web für KI-Trainingdaten abgrasen. Und dann frage ich mich: Wollen wir, dass die hier durch die Community erstellten Inhalte für das Trainieren von „KI“-Anwendungen genutzt werden?
Das Forum dient ja der Vernetzung richtiger Menschen, die Fragen, Antworten und Diskussionsbeiträge zu einem bestimmten Themenbereich verfassen, um gemeinsam zu lernen und sich gegenseitig zu unterstützen. Dieser menschenzentrierte Ansatz steht im starken Gegensatz zur Idee einer Maschine, die einen die Anworten serviert.
Wir stecken teilweise einigen Aufwand in unsere Posts. Ich persönlich möchte damit die Community und aufbauen und konkreten Menschen mit ihren Fragen helfen, fühle mich aber nicht wohl, wenn damit andere ihre (noch) gehypten und umweltschädlichen Geschäftsmodelle umsetzen.
Der Link zur robotx.txt funktioniert nicht direkt, Discourse funkt dazwischen und zeigt „Hoppla, diese Seite existiert nicht“ an. Man muss die Seite neuladen oder gleich in einem neuen Tab öffnen.
Ich bin da eher leideschaftslos. Den Nutzungsbedingungen nach sind Beiträge nicht automatisch frei lizensiert. Solange die Bots keinen unverhältnismäßigen Aufwand erzeugen, sollen sie doch crawlen. Ob die Inhalte für KI verwenden werden oder nicht hängt vermutlich nicht daran, was wir davon halten.
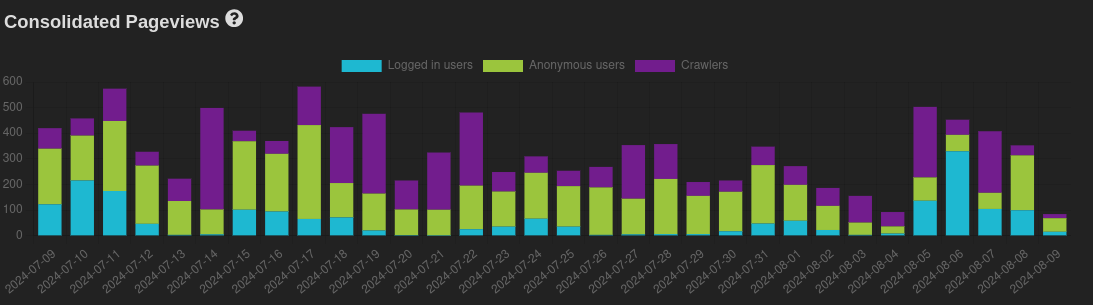
@acka47 Kann man diese Statistik noch etwas feiner aufteilen? Ich würde wäre insbesondere an einer Unterscheidung zwischen klassischen Suchmaschinen und AI-Tools interessiert, soweit leicht zuordenbar ist.
Die Indexierung in Suchmaschinen finde ich schon eine gute Sache und dafür müssen die Crawler halt die Seiten immer mal wieder abgrasen. So etwas würde ich nicht abklemmen, außer ein Crawler benimmt sich nicht und beeinträchtigt die normalen Webdienste durch zu viele Anfragen in kürzester Zeit o.ä…
Prinzipiell bin ich bei dem Ansatz mit der robots.txt auch eher etwas skeptisch. Man erreicht dadurch ja nur den Ausschluss von bekannten Crawlern, welche sich auch an solche Regeln halten. Es wäre dann immer noch sehr leicht den User-Agent bei den Anfragen zu ändern und nicht mehr geblockt zu werden. Und es könnte eher die Gefahr geben, dass man am Ende etwas ausschließt, wo eine Indexierung eigentlich nützlich sein könnte für die hilfesuchenden Menschen.
Mir ging es wohlgemerkt nie darum, sämtliche Crawler zu blocken, weshalb ich ja auch auf GitHub - ai-robots-txt/ai.robots.txt: A list of AI agents and robots to block. verweisen habe, das sich nur auf AI bots bezieht. Die Foreninhalte sollten natürlich in den gängigen Suchmaschinen indexiert werden. Auch finde ich CommonCrawl sehr sinnvoll, der sicher viel benutzt wird zum Trainieren von AI-Tools, was aber kein Grund sein sollte, den CommonCrawl-Bot zu blockieren.
Ich stimme dir zu. Es wäre aber ein Anfang und wir könnten bei Bedarf immer noch weitere Maßnahmen diskutieren. Ich habe z.B. kürzlich im Fediverse einen Ansatz gesehen, wo AI Bots, die sich nicht an die robots.txt halten, Müll-Inhalte zugespielt bekommen, um deren Lerndaten zu versauen. Finde das aber auf die Schnelle gerade nicht wieder…
Badbots, die sich nicht an die robots.txt halten, versuchen wir im Webserver mit fail2ban zu blocken. Das funktioniert auch einigermaßen gut anhand des user agent string. Die so geblockten Bots tauchen in der Auflistung von Discourse nicht auf.
Danke für die weiteren Daten! Mit einem einfachen Abgleich von der ai.robots.txt Liste habe ich folgendes bekommen: Von den insgesamt 3694 Crawler-Aufrufen sind 987 als AI-Cralwer eingestuft worden, die restlichen 2707 nicht. Die AI-Crawler-Aufrufe kommen von folgenden Tools:
Das finde ich auf den ersten Blick einerseits sehr charmant, andererseits frage ich mich, wie die sich gegen Müll bzw. falsche/manipulierte Inhalte schützen.
In-House kam der Hinweis auf Aggressive AI Harvesting of Digital Resources und dass es dazu Online-Sessions „Fedora AI Discussion Series“ gibt. Immer erst Montag des Monats 17h (unserer Zeit).
Kurzfristig sicher nicht. Sollte eine solche Abwehr aber dahingehend erfolgreich sein, dass irgendwann keine Crawler mehr kommen, könnte es mittelfristig schon den Ressourcenverbrauch reduzieren. Dafür müssten wahrscheinlich viele Seiten gleichzeitig Anti-AI-Attacken fahren, damit die Leute hinter den Crawlern mal ihre unsoziale und verschwenderische Praxis überdenken…